Posts
-
Learning, despite AI
In many ways, making certain tasks too easy too quickly can have its own pitfalls.
-
Homo numeris?
The Ukrainian government announced on May 1 that they would use a “digital person” to represent the ministry of foreign affairs for at least some of their announcements. It (she?) will be a representative for the ministry on consular affairs and is called “Victoria Shi”, which refers to Ukraine’s goal of victory in their war with Russia (or perhaps rather Russia’s war on them) and the fact that it’s an artificial intelligence.
-
Python super-schema
Interoperability is the scourge of all information systems: knowing what data means, how it is formatted, and what the semantics of the various fields are can be a daunting task. Micro-services are generally designed to process messages in potentially large quantities and, in order to do that, need to know what the messages mean. They are also generally designed to be de-coupled from each other so they can easily be replaced or updated. That means that to construct a system with a micro-service-oriented architecture, you need to have them communicate with each other and you need messages to do that. Those messages have to be well-defined and follow some ground rules.
-
DFMEA- Design Failure Mode and Effect Analysis
 Design Failure Mode and Effect Analysis (DFMEA) is a software engineering technique that can help validate design decisions or improve upon them. It takes your existing design and puts each component and link under a magnifying glass, running it through a what-if scenario. In this post, I will walk through a DFMEA of a fictional website and on-line store for a fictional florist. If you read my other blog, Applied Paranoia you may already be familiar with that application.
Design Failure Mode and Effect Analysis (DFMEA) is a software engineering technique that can help validate design decisions or improve upon them. It takes your existing design and puts each component and link under a magnifying glass, running it through a what-if scenario. In this post, I will walk through a DFMEA of a fictional website and on-line store for a fictional florist. If you read my other blog, Applied Paranoia you may already be familiar with that application. -
Lawyers- you gotta (something) them
“we will need to make sure legal requirements are at least similar across the board”
Legal requirements are something engineers don’t like to think too much about: they get in the way of progress and are generally perceived as a pain in the nether regions. There are some disparaging ideas about what lawyers do on a daily basis that seem to be prevalent in the industry. From my point of view, though, they’re not that different from software developers. They just have extra difficulties software developers don’t have: they can only test their “code” by confronting a judge. In software, we have almost instant feed-back running our code using unit tests.
-
Coaching and problem solving
I am not a teacher. According to my wife, who is a professor at law and therefore knows a thing or two about teaching, I am really, definitely not a teacher. I may have taught the occasional workshop and may try to explain things from time to time, but who am I to argue with my wife? I do find myself in the position of having to explain things a lot, though, and with today’s teleconferencing technologies, I find myself explaining to an ever-wider audience. The people on the other end of the connection are generally not novices: we share a common vocabulary and a common way of thinking about problems that makes it easier to convey whatever message I’m trying to convey. For my wife, that would be the equivalent of talking to graduate or post-graduate students. Sometimes, though, I don’t get my point accross, so I decided to read up on teaching.
-
Fundamental limitations of quantum error mitigation
People have different ways of relaxing. Some people like to watch movies, others like to listen to music, … I like to read papers, usually either about cybersecurity or quantum computing. Yesterday, I had a bit of time on my hands and decided to read on the latter: I had found an interesting paper called “Fundamental limitations of quantum error mitigation” on Arxiv, in which the authors, Ryuji Takagi, Suguru Endo, Shintaro Minagawa and Mile Gu, propose a new model for quantum error mitigation and, building on that model, find the fundamental limits.
-
Contents of the Quebec vaccine passport -- TMI?
While driving this afternoon, my wife and I had a chat about the contents of the QR code that encodes the vaccine passport here in Quebec. Apparently there had been some questions to the premier and the minister of health about “hackers” getting to its contents, and the privacy implications of such “cracks”. I had some ideas on how I’d design it, but I didn’t know how it actually worked, and I was clueless as to what a hacker could well crack (regardless of the color of their hat). Surely the contents would be signed and there’d be no more than strictly necessary encoded in the “passport”?
-
Experimental test of local observer-independence
In a recent paper published on arxiv, what was formerly a thought experiment has been realized (with minor tweaks) and, while some say this indicates there is no objective reality, I rather think it means something else.
-
Here’s something I don’t understand
Every time I look at VHDL code written by (sometimes veteran, sometimes not so much) firmware engineers, the code looks similar: a bunch of signals coming in with their direction encore in the name, and sometimes the polarity as well, but very little in the way of functionality: sometimes it’s just the datasheet pin name of the device the signal is from that made it all the way into the component I’m looking at (which, when I find that annoying, is not the top).
This part I kinda get: it’s the same issue we’ve had in software for ages, dating back before the Hungarian warthogs of the 1990s.
-
Wow, this is weird
The last time I wrote anything on this blog was more than 20 months ago. Back then, I had just come back from spending Christmas with friends and family in Florida. Since then, we’ve been in a global pandemic and no-one in their right mind would go to Florida.
-
Happy new year!
Happy new year!
2019 was an interesting year for many reasons, and I was lucky enough to finish it with family and friends in sunny Florida. 2020 also promises to be interesting, but being the nerd and nit-picker that I am, let me just rant about one minor detail…
-
Weird title in this morning's Washington Post
I subscribe to the Washington Post, not because I read it that much (I don’t have much time for that), but because I think they do a good job of balanced journalism that warrants the few dollars the subscription costs. After all, journalists need to eat too. I strongly suggest you do the same for whatever press outlet you think does a good job.
While flipping through its pages today, I came accross a title that looked, wrong: “A NASA spacecraft circling the sub stumbled upon a trail of shooting stars”. Any geek worth their salt will see what’s wrong…
-
Quantum teleportation
A bit more fun with quantum computing…
Quantum teleportation is one of those things that Star Trek fans (like myself) like to believe is a dream come true: if it’s possible to teleport qubits, surely it may be possible to teleport real-world things some day?
-
My first results with quantum computing experiments
I ran two quantum circuits on two real quantum computers and one simulator. I’ll share my results and some observations.
-
Why classical computers need exponentially more time and memory to simulate quantum computers
If you’re a bit like me, you get annoyed by the over-simplified explanations of quantum computers that have been going around since Google demonstrated quantum supremacy. One of the things that those explanations always gloss over is how it’s so much harder for a classical computer to simulate a quantum computer running what is basically linear algebra, than it is for a quantum computer to just run it. The answer to that is quantum entanglement, and in this post I will try to explain how it works.
I should point out that this means either math or meth will be involved in understanding what I’m about to write. The second option being temporary for understanding and permanent for negative effects, I recommend the first.
-
Authentication of individual users in DNP3 Secure Authentication- TB2019-001, and more
In February of this year, the DNP Technical Committee published TB2019-001: “Authentication of individual users is obsolete in DNP3-SA”. This technical bulletin, which was the first work item from the Tech Committee’s Secure Authentication Task Force to be published, was the fruit of two and a half years of work between the moment the Tech Committee decided to remove multi-user support and the moment the document was created, edited, reviewed, etc.
In this post, I will take a close look at what the impact of this document is on existing implementations of DNP3: systems, devices and firmware.
-
We live in a wonderful world
We truly live in a wonderful world that would have been impossible to imagine only a few decades ago.
Allow me to wax eloquent for a moment.
-
When RSA dies
The TL;DR:Below, I explain (as best I can):
- why the end of RSA is nigh
- why ephemeral Diffie-Hellman will survive
- what we can and cannot build on top of ephemeral Diffie-Hellman
- what this means for post-quantum PKI
- why we need a quantum-resistant digital signature algorithm
All of this is both complex and complicated. It is hard to write about this with any level of accuracy and still be readable for someone who hasn't spent an unreasonable amount of time steeped in articles about abstract math.
I gloss over a lot of details trying to keep it reasonably understandable, and I hope I haven't dumbed everything down too much. I apologize in advance both for the bits that are too hard to understand, and the bits that may seem too obvious. It's hard to find a middle ground.
-
Quantum Supremacy
A few days ago, the Financial Times reported that “Google claims to have reached quantum supremacy”. The paper in question, available here, explains how they reached this milestone, and how they proved it. It does beg the question, though: what is quantum supremacy?
-
That lunch wasn't free after all
The Spectre and Meltdown bugs have shown that the free lunch was indeed over a decade ago. We should therefore stop attempting to exploit instruction-level parallelism with ever more complex stacks and ever more complex pipelines and branch predictors, and start exploiting the inherent parallelism of hardware. In order to do that, we need to change the way we thing about software from our current imperative way of thinking to a more declarative way of thinking. At the same time, we need to change the way our computers think about software to allow them to exploit this more declarative style to use their inherent parallelism and free up die space currently used for caches and ILP.
-
reboot
Readers of this blog may wonder what happened: the layout is completely different, but the thing is also a lot faster..??!
The reason for this is simple: I stopped using Wordpress. It was giving me more trouble than it was worth, so I decided to move the site, and all of its contents, to Jekyll. This has the advantage of being able to write directly in Vim, with the only minor disadvantage of having to build the site.
Some formatting will need to be fixed for older posts, and I will start doing that when I have a bit of time. In the mean time, I will try to just post stuff out.
Some of what I post may be PDF files: I’ve been using LaTeX a lot lately, and have some interesting stuff that presents better as PDFs. I’ll see how that turns out as well.
Also: please let me know about any bugs you see: the site is large enough for me to not be able to re-read everything, so there may be a few bugs I’ve missed.
-
The Logging "problem"
A recurring problem in real-time industrial devices is logging: you want to log all the information you need to diagnose a problem, but you don’t want to slow down your system and miss timing constraints, or unnecessarily burden your system when there are no problems. On the other hand, you often don’t know that there is a problem to be diagnosed (and therefore logged) before there is an actual problem, in which case you may be too late to start your logs.
The solution seems obvious: just look a minute or so into the future and, if any trouble is brewing, start logging. But as a wise person once said: “Always in motion the future is.” In the real world, we need real solutions.
-
The Equifax data breach: what we know, what you can do, what's next
The TL;DR: TL;DR mindmap
TL;DR mindmap -
The problem with making things too easy
The TL;DR:
The thing with making things easier is that it makes mediocre people seem competent and incompetent people seem mediocre...
— Ronald (@blytkerchan) July 21, 2017 -
To those of you who don't speak French and follow me on Twitter
As may know, France is going to the polls tomorrow to elect a new president. They have a choice between an unaffiliated centrist, Emmanuel Macron, and an unavowed fascist, Marine le Pen.
I am not French, but my wife is, and my children have a number citizenships among which French is one they all share. Aside from that, the stakes for the French election are much higher than they were for the Dutch elections, a few months ago, and arguably even for the American presidential election last November.
Let me explain those assertions.
-
This guy is out of his mind (and lucky if he can still see)
This guy has to be completely bonkers: he wrote an application in C# (would not have my language of choice) to detect a human face in a live video feed and point a laser at it.
-
"Police hack PGP server" -- really?
This afternoon, this headline caught my attention: “Police hack PGP server with 3.6 million messages from organized crime BlackBerrys”. When I read it, I thought: “either the journalist/title writer got it wrong, or PGP is broken”.
-
Writing unmaintainable code in five easy steps
I have recently had to modify some code that, to say the least, was very hard to maintain – or refactor, for that matter.
The following are a few, firmly tongue-in-cheek, steps to make sure your code is thoroughly frustrating to whoever needs to maintain it after you.
-
Meetings, meetings, and more meetings
Recently, I spent a significant part of the day in a meeting reviewing the year’s progress on several projects, including the introduction of an agile methodology – Scrum. The approach in the meeting was simple: write on a sticky note what we did well, and on another what we should not repeat or how we should improve. The subject was “Scrum/agile”. I only wrote one sticky note: “get rid of Scrum”.
The TL;DR:
Scrum, in my opinion, is (moderately) useful for small teams with a single, short-term project -- something like a web application. The overhead it imposes _vastly_ outweighs the benefits for larger teams and larger projects. -
Debugging — or: what I do for a living
I am often asked by friends and acquaintances of various backgrounds, what I do for a living. Depending on my mood at the time, I can answer in any number of ways, but invariably my answers are met with blank stares, questions that clearly demonstrate that I have once again failed to make myself understood and an eventual change of subject.
-
Really, Twitterverse?
 Felicia, our cat, relaxing
Felicia, our cat, relaxingThe Twitterverse has spoken, quietly, with a single vote – a cat it is…
-
Setting up a Xubuntu-based kiosk
This is another “HOWTO” post – setting up a Xubuntu-based kiosk, which I did to make a new “TV” for my kids.
-
Technocracy II
In my previous post, I described technocracy as something that is positive in project and product management, and in team organization. In this post, to supply a boundary to my previous text, I will make the case for the opposite.
-
Technocracy
In a discussion with a “Product Owner” recently, I told him I take a more technocratic approach to project management than they did. We discussed different project management styles for the next hour or so.
TL;DR: I believe that- to effectively and efficiently run a large team of developers who are collectively responsible for a product with a large code-base, that team needs to be organized as a network of smaller teams with experts leading each of those smaller teams, and
- to successfully manage an "agile" development team and create a viable product, one has to have a vision and break it down from there.
-
Real-time thirsty
The TL;DR:
In this post, I show using a fictitious example why real-time systems are defined by their worst-case timing rather than their average-case timing.Imagine you’re running a coffee shop – not the kind you find in Amsterdam, but one where they actually serve coffee. Your customers are generally in a hurry, so they just want to get a cup of coffee, pay and leave to catch their plane, train or automobile. To attract more customers and appeal to the Geek crowd, you name your coffee shop “Real-Time Thirsty” and promise an “Average case serving within one minute!”.
While you get many customers, you’re not getting the Geeks-in-a-hurry crowd you were expecting.
-
Setting up Cygwin for X forwarding
The TL;DR:
This is one of those "recipe" posts that tend to be useful if you happen to want to do exactly what I just did. The end result of this one is a Windows shortcut called "Linux terminal" on the desktop, that opens up an SSH terminal to a Linux box, with X forwarding. -
Shutting down servers
I used to have a server with five operating systems, running in VMs, merrily humming away compiling whatever I coded. I say “used to have” because I shut it down a few weeks ago. Now, I have those same operating systems, as well as a large number of others, running on systems I don’t need to worry about.
-
Checked output iterator
While writing about security – which takes a great deal of my time lately, which is one of the reasons I haven’t updated my blog as often as I usually would – I came to the conclusion that, while I recommend using STL algorithms, iterators and containers for safety purposes that doesn’t solve the problem when the standard algorithms don’t check the validity of their output ranges.
-
Schoenmaker, blijf bij je leest (Cobbler, stick to your last)
This is an old Dutch saying, which probably has its origins in a village with a particularly opinionated cobbler.
I am not one to stick to my last – but if I were a cobbler, I don’t think I’d be that cobbler: I like to know what I’m doing.
-
Interesting modifications to the Lamport queue, part II
In the previous installment, on this subject, I described a few modifications to the Lamport queue introduced by Nhat Minh Le et al. to relax operations on shared state as much as possible, while maintaining correctness.
In this article, I will discuss the further optimizations to reduce the number of operations on shared state, thus eliminating the need for memory barriers completely in many cases.
-
Interesting modifications to the Lamport queue
While researching lock-free queue algorithms, I came across a few articles that made some interesting modifications to the Lamport queue. One made it more efficient by exploiting C11’s new memory model, while another made it more efficient by using cache locality. As I found the first one to be more interesting, and the refinements more useful for general multi-threaded programming, I thought I’d explain that one in a bit more detail.
-
Progress in DNP3 security
In July last year, I discussed why Adam Crain and Chris Sistrunk fuzzed DNP3 stacks in devices from various vendors, finding many issues along the way (see project Robus). This time, I’ll provide a bit of an overview of what has happened since.
-
CIS: "Protecting" code in stead of data
The Windows API contains a synchronization primitive that is a mutual exclusion device, but is also a colossal misnomer. I mean, of course, the
CRITICAL_SECTION. -
CIS: Lock Leaks
The two most popular threading APIs, the Windows API and pthreads, both have the same basic way of locking and unlocking a mutex – that is, with two separate functions. This leaves the code prone to lock leak: the thread that acquired a lock doesn’t release it because an error occurred.
-
CIS: Unexpected Coupling
One of the most common problems with synchronization occurs when things need each other that you didn’t expect to need each other.
-
Git demystification
There are a few misconceptions I hear about Git that I find should be cleared up a bit, so here goes:
-
Three ideas you should steal from Continuous Integration
I like Continuous Integration – a lot. Small incremental changes, continuous testing, continuous builds: these are Good Things. They provide statistics, things you can measure your progress with. But Continuous Integration requires an investment on the part of the development team, the testers, etc. There are, however, a few things you can adopt right now so, I decided to give you a list of things I think you should adopt.
-
Eliminating waste as a way to optimize
I recently had a chance to work on an implementation of an Arachnida-based web server that had started using a lot of memory as new features were being added.
Arachnida itself is pretty lean and comes with a number of tools to help build web services in industrial devices, but it is not an “app in a box”: some assembly is required and you have to make some of the parts yourself.
-
Technical documentation
Developers tend to have a very low opinion of technical documentation: it is often wrong, partial, unclear and not worth the trouble of reading. This is, in part, a self-fulfilling prophecy: such low opinions of technical documentation results in them not being read, and not being invested in.
-
The story of "Depends"
Today, I announced on behalf of my company, Vlinder Software, that we would no longer be supporting “Depends”, the dependency tracker. I think it may be worthwhile to tell you a by about the history of Depends, how it became a product of Vlinder Software, and why it no longer is one.
-
Bayes' theorem in non-functional requirements analysis -- an example
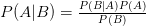 Bayes' theorem
Bayes' theoremI am not a mathematician, but I do like Bayes’ theorem for non-functional requirements analysis – and I’d like to present an example of its application1.
-
I was actually going to give a theoretical example of availability requirements, but then a real example popped up… ↩
-
-
Globe and Mail: Canada lacks law that defines, protects trade secrets
According to the Globe and Mail (Iain Marlow, 20 May 2015) the 32-count indictment against six Chinese nationals who allegedly used their positions to obtain intellectual property from universities and businesses in the U.S. and then take that knowledge home to China, would not be possible here: “Canadian observers say the 32 count indictment, which was unsealed late on Monday, highlights the prevalence and severity of industrial espionage in North America, and underscores the need for Canada to adopt more stringent laws. Canada has no dedicated act on trade secrets and economic espionage and has not successfully prosecuted a similar case, experts say.”
-
Why I didn't buy a new iPad today
Behavioural economists will tell you that the “happy high” you get from buying a new toy, a new device, a new computer, a new car or a new house usually wares off within three months. It’s called the ever-receding horizon of happiness (or something like that – something close to the ever-receding hair line) and it’s why I have a small car (just big enough for day-to-day requirements but not big enough to take the whole family on vacation), a fairly crappy laptop computer (good enough to run OpenOffice Write and an SSH client on, but not good enough to compile FPGA firmware or big chunks of software in any hurry, but that’s what the SSH client is there for) and why I’ve had the same iPad for the last five years or so.
-
Implementing time-outs (safely)
Thyme is a herb that grows in gardens.
-
Bungee coding
For the last few weeks, I’ve been doing what you might call bungee coding: going from high-level to low-level code and back. This week, a whole team is doing it – fun!
-
Adding SPI support to the BrainF interpreter
While at Chicago’s O’Hare airport, waiting for my connecting flight to Reno, I had a bit of time to start coding on my BrainF interpreter again – once I had found an outlet, that is1. My goal was to add something that would allow something else to communicate with the interpreter. There are a few buses I like for this kind of thing, and SPI is one of them.
-
Apparently, power outlets at Chicago O’Hare are a rare commodity, to the point that their internal website points you to “Power stations” of which there were three in my vacinity, but all of them were fully – ehm.. – used. I finally found an outlet in the foodcourt with a gentleman standing next to it, but only using one socket, so I connected my laptop the the other so socket and a small constellation of devices to the various USB ports on my laptop… ↩
-
-
Miss(ed) Communication
 Miss(ed) Communication
Miss(ed) Communication -
Radical Refactoring: Breaking Changes
One of the most common sources of bugs is ambiguity: some too-subtle API change that’s missed in a library update and introduces a subtle bug, that finally only gets found out in the field. My answer to that problem is radical: make changes breaking changes – make sure the code just won’t compile unless fixed: the compiler is generally better at finding things you missed than you are.
-
Improving the BrainF interpreter
As I wrote in a previous post, I wrote a BrainF interpreter in VHDL over a week-end. I decided to improve it a bit.
-
Radical Refactoring: Have the compiler to (some of) the reviewing
One of the most common sources of bugs is ambiguity: some too-subtle API change that’s missed in a library update and introduces a subtle bug, that finally only gets found out in the field. My answer to that problem is radical: make changes breaking changes – make sure the code just won’t compile unless fixed: the compiler is generally better at finding things you missed than you are.
-
Writing a BrainF interpreter ... in VHDL
I’ve written parsers and interpreters before, but usually in C++ or, if I was feeling like doing all of the hard work myself, in C.
-
A different take on the "optimize by puzzle" problem
I explained the problem I presented in my previous post to my wife overt dinner yesterday. She’s a professor at law and a very intelligent person, but has no notion of set theory, graph theory, or algorithms. I’m sure many of my colleagues run into similar problems, so I thought I’d share the analogies I used to explain the problem, and the solution. I didn’t get to explaining how to arrive at computational complexity, though.
-
Optimization by puzzle
Given a
queryroutine that takes a name and may return several, write a routine that takes a single name and returns a set of names for which each of the following is true:- For each name in the set,
queryhas been called exactly once. - All the results from the calls to
queryare included in the set - the parameter to the routine is not included in the set
You may assume the following:
- For each name in the set,
-
Looking for bugs (in several wrong places)
I recently went on a bug-hunt in a huge system that I knew next to nothing about. The reason I went on this bug-hunt was because, although I didn’t know the system itself, I knew what the system was supposed to do, and I can read and write all the programming languages involved in developing the system (C++, C and VHDL). I’m also very familiar with the protocol of which the implementation was buggy, so not knowing the system was a minor inconvenience.
These are some notes I took during the bug-hunt, some of which intentionally kept vague so as to protect the guilty.
-
Re: E-mail
The Globe&Mail; dedicated half a page of the Report on Business section to managing your inbox today. People who work with me know that
- if you want to get ahold of me quickly, E-mail is not the way to go
- if you want a thought-out, thorough response, E-mail is the way to go
-
ICS Security: Current and Future Focus
The flurry of DNP3-related vulnerabilities reported to ICS-CERT as part of Automatak’s project Robus seems to have subsided a bit, so it may be time to take a look at where we are regarding ICS security, and where we might be going next.
-
Is Open Source software security falling apart?
There have been a number of well-publicized security flaws in open source software lately – the most well-publicized of course being the OpenSSL Heartbleed bug1.
Then there’s the demise of Truecrypt, recent bugs in GnuTLS and recent bugs in the Linux kernel.
So, is there a systemic problem with Open Source software? Does proprietary software have the same problem?
-
OpenSSL is very widely used, which makes its effect on the Internet enormous, and the effect of bugs in the protocol implementation huge. That explains why such bugs are so well-publicized. Another factor in the publicity is the name of the bug (which was very well-found). ↩
-
-
"A camel is a horse designed by a committee"
I don’t usually use this blog to vent frustration, but I’ve been reading standards lately…
There are four versions of the horse:
-
Pony. Horses as the Good Lord intended them. Strong and sturdy, yet soft and cuddly; obedient yet intelligent; and I’m told they’re rather tasty too!
-
Horse. All the qualities of the pony, without the esthetics.
-
Donkey. The beta version of the pony: strong and sturdy, but none of the frills and quite a few bugs in the programming. Also: they don’t taste nearly as good (or so I’m told).
-
Ass. What the beta version became when the PMO took over.
-
Cow. A forked-off project from the (then open-source) Horse project that went for taste, combined with a bigger ass for the workload (in the form of an ox – you didn’t think I misspelled ass, did you?)
-
Dromedary. When some of the committee members got tired of trying to reach a consensus, they took what they had and ran with it – even if it’s running was more than a bit awkward.
-
Camel. None of the looks. Some of the features. Some features you didn’t think a horse should have. Some you didn’t think a horse could have. More of the smell. Much, much more.
When you count, that doesn’t add up to four, does it?
That’s what design by committee is all about!
-
-
What the industry should do with the upcoming Aegis release
Automatak will be releasing the Aegis fuzzing tool publicly and for free for the first time in a few days. Like I said yesterday:
Can hardly wait: "2 weeks until Aegis™ release" http://t.co/KrQkrbb9a9
— Ronald (@blytkerchan) March 1, 2014to which Adam replied:
@blytkerchan I just hope the industry is ready!
— Code Monkey Hate Bug (@jadamcrain) March 1, 2014I don’t think the industry is ready – and here’s why.
-
Optimizing with type lists
In this post, I will take a brief look at how using type lists can help optimize certain applications.
-
A functional version of the KMP algorithm
For one of the projects I’m working on, I needed a compile-time version of the KMP algorithm in C++. I started by making the algorithm functional.
-
ICS security and regulatory requirements
In North America, ICS security, as regards the electricity grid, is regulated by NERC, which provides and enforces, among other things, the Critical Infrastructure Protection (CIP) standards.
In this post, I’ll provide a quick overview of those standards, provisions slightly more in-depth information than in my previous post.
-
The Crain-Sistrunk vulnerabilities
In the two previous posts, I’ve shown that industrial control systems – ICSs – are becoming more pervasive, and that they rely on security through obscurity.
Now, let’s make the link with current events.
-
The importance of ICS security: ICS communications
For an ICS, having communications abilities generally means implementing some machine-to-machine communications protocol, such as DNP3 or Modbus. These protocols, which allow the device to report data to a “master” device and take their cue from those devices w.r.t. things they should be doing, are generally not designed with security in mind: most of them do not require, or expect, user authentication for any commands you might send them, and don’t implement anything approaching what you’d expect from, e.g., a bank (confidentiality, integrity, authentication, authorization, non-repudiation).
-
The importance of ICS security: pervasiveness of ICSs
Industrial Control Systems (ICSs) are becoming pervasive throughout all branches of industry and all parts of our infrastructure: they are a part of every part of the electricity grid, from the nuclear power station to your home; they’re found in the traffic lights of virtually every crossing; they regulate train traffic; they run the cookie factory that makes your favorite cookies and pack the pills your doctor prescribed.
-
Perl: Practical or Pathologically Eclectic? Both?
There are two canonical acronyms for Perl: “Practical Extraction and Report Language” and “Pathologically Eclectic Rubbish Lister”. Arguably, Perl can be both.
-
A few thoughts on BitCoin
Mindmap of a few thoughts on BitCoin I’d meant to turn into prose (still might)
-
Qt to quickly write a GUI app
Today, my wife asked me to write an app that would tell her to sit straight every 15 minutes. I know apps like that already exist and I could’ve pointed her to one, but I decided to write one myself. The result is tannez-moi (which is French for “bother me”).
-
The benefits of formal, executable specifications
While a specification should not specify the C++ code that should be implemented for the specified feature, it should specify the feature in a verifiable manner. In some cases, formal – and even executable – specifications can be of great help.
-
Why #fixthathouse?
Those of you who follow me on Twitter might wonder why, all of a sudden, I started tweeting assertions with the #fixthathouse hashtag. The reason is simple, CBC The House made me do it.
-
Common nonsense: the charter of Quebec Values

Four of these need not apply for a government job in Quebec if the new PQ charter of values becomes law. Can you pick the one that might still get the job?
-
Sometimes, your right hand should know what your left hand is doing
Especially if you’re a compiler…
-
Conditional in-place merge algorithm
Say you have a sorted sequence of objects.
Go ahead, say: “I have a sorted sequence of objects!”
Now say it’s fairly cheap to copy those objects, you need to be space-efficient and your sequence may have partial duplicates – i.e. objects that, under some conditions, could be merged together using some transformation.
OK, so don’t say it. It’s true anyway. Now we need an algorithm to
-
check for each pair of objects in the sequence whether they can be transformed into a single object
-
apply the transformation if need be
Let’s have a look at that algorithm.
-
-
Why I decided Vlinder Software should stop selling Funky
If you follow the News feed from Vlinder Software’s site you know that I’ve posted an announcement saying Funky is now in its end-of-life cycle. This is our first product to enter end-of-life, but what it basically means is that we won’t actively work on improving the software anymore.
If you’ve been following me for a while, you’ll know that I am the founder and sole proprietor of Vlinder Software, as well as the CEO and an Analyst. I don’t usually sign off as CEO, but this is one of those decisions that is mine alone to take. In this post, I will explain why.
-
Structure alignment and padding
In my previous post on the subject, I talked about using magic numbers and versions, alignment, and later added a note about endianness after a suggestion from Michel Fortin. This time, I’ll talk about padding, how the sizeof operator can be misleading and how to debug padding and alignment errors.
-
Flawed ways of working: centrally managed version control
-
Minor changes in style
I am not usually one to make much of a fuss about coding style: as long as the code is easily readable, I don’t much care whether you use tabs or spaces to indent, how you align your curly quotes, etc. There’s really only two things I do care about when reading new code:
- is it easy to read the code without being misled by it?
- does the new code integrate well with the rest of the code? I do have a few suggestions, though, but above all, I recognize it can be difficult to change habits – and therefore to change one’s coding style.
-
Even in Quebec, Winter is not the only season
An just to remind myself and some of my colleagues, I drew this on the office whiteboard yesterday:

-
What happens if structures aren't well-designed
In my previous post, I explained how to design a structure for persisting and communicating. I didn’t say why I explained it – just that things get frustrating if these simple rules aren’t followed. In this post, I will tell you why I wrote the previous one.
-
How to design a struct for storage or communicating
One of the most common ways of “persisting” or communicating data in an embedded device is to just dump it into persistent storage or onto the wire: rather than generating XML, JSON or some other format which would later have to be parsed and which takes a lot of resources both ways, both in terms of CPU time to generate and parse and in terms of storage overhead, dumping binary data into storage or onto the wire has only the – inevitable – overhead of accessing storage/the wire itself. There are, however, several caveats to this, some of which I run into on a more-or-less regular basis when trying to decipher some of that data, so in stead of just being frustrated with hard-to-decipher data, I choose to describe how it should be done in stead.
Note that I am by no means advocating anything more than a few simple rules to follow when dumping data. Particularly, I am not going to advocate using XML, JSON or any other intermediary form: each of those has their place, but they neither should be considered to solve the problems faced when trying to access binary data, nor can they replace binary data.
-
Exceptions and Embedded Devices
Lately, I’ve had a number of discussions on this subject, in which the same questions cropped up again and again:
-
should exceptions be used in embedded devices?
-
should exceptions occur in “normal operation” (i.e. is every exception a bug)?
My answer to these two questions are yes and yes (no) resp.: exceptions can and should be used (appropriately) in embedded devices and exceptions may occur during normal operation (i.e. not every exception that occurs is a bug).
-
-
Quick Summary: Synchronization in Next-Generation Telecom Networks
This is a quick summary of the ComSoc webinar on Synchronization in Next-Generation Telecom Networks
Over the last few years, communications networks have changed radically: their use has gone from predominantly voice to predominantly data and they have themselves gone from predominantly synchronous networks to predominantly packet networks.
Time synchronization requirements, in terms of quality of time, have only gotten stricter, so new methods for clock synchronization are now required - i.e. NTP can’t do the job to the level of accuracy that’s needed.
-
On the importance of clear technical specifications
Even when the code is working like a charm, technical specifications – and their different interpretations by different people – can lead to confusion and hours-long debugging sessions.
-
Plain and clear cases of "don't do that - fix your code in stead"
For the last few days, a discussion (that has become heated from time to time) has been going on on the comp.lang.c usenet group. The subject is a “signal anomaly”: the OP wants to catch SIGSEGV and carry on along its merry way.
-
When hardware foils software -- and then helps it out!
Sometimes, an oscilloscope can come in very handy.
-
Please use my time wisely
Just because I charge by the hour, that doesn’t mean you should be wasting my time…
This morning, in the wee hours of the morning (time differences can keep you up at night, as can young children), I spent more than an hour and a half doing makework. Most of that work, probably all of it, could have been avoided if I’d been given a working setup rather than a huge chunk of source code and a recipe to make it work. Granted, the recipe did work, but it was still a huge waste of time.
-
Why CS shouldn't be taught before high school (and coding for kids is a bad idea)
An introduction to computer science was part of my high school curriculum. I was about 16 years old at the time and had been coding in Basic and Pascal for a few years already - I was just getting started with C. This part of the curriculum was a complete waste of time. Not because I had books that taught me better than my teacher ever could, but because, in order to make it easier for us, the programming language we had to use was a version of Pascal … translated to Dutch.
-
Sometimes, use-cases just aren't what you need
I’ve written about use-cases on this blog before (parts one, two and three of the sidebar on use-cases in my podcast come to mind) but I haven’t really talked about when to avoid them.
When you get a new piece of hardware and a vague set of requirements, what do you do?
- try to get the most out of the hardware you possible can
- design to meet the need, using use-cases to guide you
- a bit of a, a bit of b
- other… (leave a comment)
-
Robustness analysis: the fundamentals
Up until 2008, the global economy was humming along on what seemed like smooth sailing, doing a nice twenty knots on clear waters, with only an occasional radio message saying there were icebergs up ahead. Surely none of that was anything to be worried about: this new economy was well-designed, after all. Redundant and unnecessary checks had been removed but, in order for the economy to be robust, the engineers of the economy had made sure that at least two whole compartments could be flooded before anything really nasty would happen.
Sound familiar?
-
Robustness analysis: finding fault(s)
When working on a large project, implementing a system that has to run 24/7 and handle significant peak loads of communication, at some point, you have to ask yourself how robust your solution really is. You have to ascertain that it meets the goals you have set out and will consistently do so. There are diverse ways of doing this. Some are more efficient than others. In this article, I will discuss some of the methods I have found useful in the past.
-
I'll be back (soon)
Those of you who have been following this blog or the podcast may be wondering why I’ve been silent lately. The answer to that is simple: lack of sleep. My baby boy is starting to sleep nights, though, and some time should hopefully clear in my schedule to pick up the podcast where I left it, and to write some more posts on this blog. In the mean time: patience is a virtue – and sleep an under-rated commodity.
-
Changing an API in subtle, unpredictable ways
Many seasoned Windows systems programmers will know that you can wait for the death of a thread with
WaitForSingleObjectand for the deaths of multiple threads with its bigger brother,WaitForMultipleObjects. Big brother changes its behavior on some platforms, though – as I just found out myself, the hard way. -
Opening a support ticket with Microsoft (or: how not to support your customers)
I had to open a support ticket with Microsoft today: I found a bug in the TCP/IP stack of Windows Embedded Compact 7 that I wanted them to know about (and to fix). I also wanted to know when it would be fixed – after all, the bug is critical and the company I work for is a Microsoft Gold partner, so I had a reasonably high expectation of service.
Suffice it to say I was disappointed.
-
Winter wallpapers
As has become my custom (at least since this summer) I’ve changed the theme a few days go, at the start of the season. Here are the associated wallpaper images…
-
Sleep(...)
For those of you waiting for the next installment of “C++ for the self-taught”: I’m on parental leave at the moment. The podcast (and the rest of the blog) will be back in a few weeks.
-
Radix Sort

The Radix Sort algorithm is a stable sorting algorithm that allows you to sort a series of numerical values in linear time. What amazed me, however, is that it is also a natural approach to sorting: this is a picture of my daughter applying a radix sort to her homework (without knowing it’s a radix sort, of course, but after explaining the algorithm perfectly)!
-
The underestimated legacy of Dennis Ritchie
Dennis Ritchie is the inventor of the C programming language, which is the ancestor of a whole family of programming languages that includes C++, Java and C# – probably the three most popular programming languages today – as well as D and Objective-C, which are less popular but significant nonetheless.
-
Making the enabling of online copyright infringement itself an infringement of copyright
Bill C-11 amends the Copyright Act in several different ways. One of the states purposes of those amendments is to “make the enabling of online copyright infringement itself an infringement of copyright”. While I can understand that this adds significant new protections to copyrighted materials, I think this may quickly become either unenforceable, or introduce serious new restrictions on how communications over the Internet can legally take place. It all hinges on the definition of “enabling”, however.
-
Harper government reintroduces toughened online copyright law
In the Vancouver Sun: bill C-32 from last session has been re-introduced (probably with some modification – I haven’t had a chance to read the bill yet) and is far more likely to pass, now that there’s a conservative majority in Parliament.
Update Oct 8, 2008: the re-introduced Copyright Modernization Act is numbered C-11, and is available here.
-
Autumn is here - and so is the autumn banner
OK, autumn has been here for about a week already, and the banner was ready two months ago, but I only now had both the time and the inclination to put it up…
You might remember that the corresponding desktop wallpapers are in the Canada Day post.
-
Moving to GitHub
I will be moving my open source projects (yes, all of them) to GitHub.
-
Eclipse: kudos
One of the things I like about Eclipse is the way it is designed. I’m not talking about the GUI when I say that - although the GUI is arguably well-designed as well: I mean the way hundreds of pieces fit together to make Eclipse an IDE for Java, C, C++, PHP, Python, …, etc.
-
You, according to Google Analytics
This blog uses Google Analytics, which provides a treasure-trove of information about the site’s visitors. To use that information to improve the site, it has to be parsed.
Here’s a sketch of what a typical user may look like - and what that tells me about what I should do with the site.
-
shtrict: a very restricted shell for *nix
I needed a restricted shell for my shell server - the one that’s available from outside my firewall, so I wrote one. You can download it under the terms of the GNU General Public License, version 3.
-
New GnuPG key
For those who want to be able to verify .deb packages I make: I have a new GnuPG key.
Type bits/keyID Date User ID pub 2048R/6D3CD07B 2011-07-20 Ronald Landheer-Cieslak (Software Analyst) <rlc@vlinder.ca> Hash=E0C9DE42CFF88A35CACE3EB488A1783E Fingerprint=9DAC FA3D D7A5 001F A0B2 DA59 5E0C 4AF1 6D3C D07BYou can download it from keys.gnupg.net
-
From #NotW in the GMT morning to #UBB in the EDT afternoon -- an example of devoted journalism
I’ve just been catching up on my Twitter account’s updates for today, where possibly the only non-tech person I follow, a politics journalist from the CBC called Kady O’Malley (@kady and @anotherkady) is still tweeting after 15 hours.
She started liveblogging the #NotW scandal in the UK this morning at 6 am and continued on the CRTC Usage-Based Billing hearings when those started.
This is the same Kady O’Malley that answers the questions sent to CBC Radio’s The House in the “That’s a good question” section.
I already knew CBC Radio provides well-informed, balanced journalism (I don’t watch TV so I don’t know about CBC TV) but now I know how they do it: this is one example the people at News International should follow – rather than hacking into people’s voicemail and giving journalism a bad name.
-
"Changer son fusil d'épaule"
Sometimes, when all else fails, you have to change your tack.
-
Happy Canada Day
On the occasion of Canada day, I thought I’d put up the Canada-themed autumn wallpapers I’d prepared.
-
Hardware designers, please, think of us!
One of the most time-consuming tasks in embedded software development can be device driver debugging. Especially if that debugging has to be done in a real-time system without disturbing its real-time characteristics. This usually amounts to producing an output signal on a pin of the CPU and probing the output to see what’s going on. In order to be able to do that, the people who design the hardware have to keep in mind that the people who design the software will have some debugging to do on the final hardware – even if it’s just to make sure everything is working OK.
-
Canada Post Labor Dispute -- Resolved?
I’ve been watching the Canada Post labor dispute from afar over Twitter and saw the back-to-work bill pass on third reading. Does that mean the dispute is over? I don’t think so…
-
Lonely Planet's Travel Top Ten
Lonely Planet came out with a book on their top-ten places to visit recently. In light of recent events, some of their choices merit revision and as I don’t have anything better to do right now, I thought I’d do a bit of revision on my iPod…
-
The Manchester Baby is 63 years old today
The first “modern” programmable computer with 32 words of memory, is 63 years old today.

A revised history of the Manchester Baby, in two parts, by B. Jack Copeland from the University of Canterbury in Christchurch, New Zealand, is available here and here – a really interesting read.
-
Summer is here
Summer is here, so it’s time to update desktop backgrounds and site headers with something a bit more summery.
This wallpaper of course has the Vlinder logo and the url of this website but, more prominently, it has a lily flower - which also figures prominently (but stylized) on the flag of the Canadian province I live in.
-
Functional Programming at Compile-Time
In the previous installment I talked about functional programming a bit, introducing the idea of functors and lambda expressions. This time, we will look at another type of functional programming: a type that is done at compile-time.
-
From XKCD.com: Copyright

-
Using Ranges and Functional Programming in C++
C++ is a very versatile language. Among other things, you can do generic meta-programming and functional programming in C++, as well as the better-known facilities for procedural and object-oriented programming. In this installment, we will look at the functional programming facilities in the now-current C++ standard (C++03) as well as the upcoming C++0x standard. We will look at what a closure is and how to apply one to a range, but we will first look at some simpler uses of ranges – to warm up.
-
Starting Python - 99 bottles of beer
After a brief discussion on the subject on StackOverflow chat, I’ve decided to try my hand at Python, using the on-line IDE at Ideone.com. Here is my rendering of “99 bottles of beer” in Python…
-
Why I Recommend BrainF--- (and what I recommend it for)
BrainFuck is an esoteric Turing-complete programming language that consists of only the bare minimum commands for Turing-completeness. It is exactly this bare-minimum-ness that makes it an interesting language - although at first a bit awkward to wrap your head around.
>>++++[<+++++>-]<+++[<+++++>-]<-.------.---------.>>++++++++[<++++ ++++>-]<.[-]++++[<+++++>-]<-.----------.---.+++++.----------.+.+++ ++++++++++.>>+++++++[<+++++++>-]<---.[-]+++[<----->-]<.--. -
Shining light on bugs: testing
Bugs like to hide in the darker corners of the code: the parts that are least exercised, less well-structured. They don’t react to light very well. tests are like a spotlight that you shine upon specific pieces of the code. The first time you do that – especially if the code has been around a while – the bugs will come crawling out of the woodworks.
-
C++0b
The C++ standard committee has been meeting in Madrid and has, according to the latest news, approved the new C++ standard. As Michael Wong said on his C/C++ Cafe Blog, C++0x is now C++0b – though it might be C++0c by the time ISO gets done with it.
-
Ranges
-
Geek Mythology: Women and the Start of Software Engineering
According to Geek mythology, when Charles Babbage had invented the Analytical Engine, he sat back and said: “Behold! I have created the first pocket calculator!”. Of course, he hadn’t actually built the thing yet, and lacket the practical skill to do so. When it finally was built, there wasn’t a pocket large enough on Earth to put it in. Thus was the inception of the hardware engineering discipline.
While hardware had gotten off to a good start, software took a more practical approach: when Ada Lovelace heard of the Analytical Engine, she said to herself: “Forsooth, such a mighty machine needeth a touche feminine if ever it is to serve a purpose” and proceeded to write the first computer program. It took several decades for the hardware engineering discipline to catch up with the software engineering discipline and for the two to come together and actually do something useful.
-
The Evolution of the Software Engineering Practice Faced With The Knowledge That "Bugs Must Exist"
Though laudable, the quest for bug-free software is doomed to failure. This should be news to no-one as the argument for this is as old as I am.
-
A bulldog approach to bugs
The only bugs I like are butterflies - and even then, only a specific blue butterfly that happens to be a drawing. Aside from those, I spend a lot of time rooting them out.
I advocate what you might call a bulldog approach to bugs: track them, hunt them down, kill them. Don’t let go until you’re sure they’re dead. This might seem overly agressive, but remember we’re talking about software errors here - not actual living beings.
-
Applying the Barton-Nackman idiom
It is amazing how much code you can cram into a single line, and how much magic happens behind the scenes when you do.
-
A "brilliant" idea (?)
For a few days now, I’ve been carrying an idea around for a new app I could really use for my projects: something that integrates requirements management, risk management, workflow, billing, bug/issue tracking, action items, etc. with the code repositories. Wouldn’t that be fun?
-
The Art and Science of Risk Management
I like to take a rational approach to risk management: identify risks and opportunities, their probability and their impact, maximize the impact and probability of opportunities and minimize those of risks. In this article, I explain a bit of my approach, I expound upon risk dependencies, based on a recent article by Tak Wah Kwan and Hareton K.N. Leung, and I offer some practical advice.
-
The Observer Pattern
In this installment of C++ for the self-taught, we will be looking at the Observer pattern: we will be starting the implementation of the proxy-part of our SOCKS server by accepting connections and servicing them.
-
A new look and a new address
Due to some technical difficulties I was having with the previous installation of the software running this site, I decided to re-install the software from scratch and, while at it, change the address from landheer-cieslak.com to rlc.vlinder.ca. The look has been updated a bit and some further improvements will take place over the next few weeks.
-
Security Awareness and Embedded Software
In a recent interview with Ivan Arce of Core Security Technologies by Gary McGraw of Cigital, Arce made the point that embedded systems are becoming a security issue. At about the same time, US Army General Keith B. Alexander, director of the US National Security Agency, said that a separate secure network needs to be created for critical civilian infrastructure. They are probably both right.
-
How error messages can backfire
Error messages should provide enough information for the user to correct their error, but they shouldn’t provide any more than that, or malicious users could abuse them - as shown recently with the ASP.NET server.
-
Testing Lock-Free Software
When a test has been running non-stop for over six months, beating the heck out of an algorithm, can we be confident the algorithm is OK?
-
Event-driven software, step 1: select
In this installment, we will look at the basic networking functions and start looking at event-driven software design. Starring in this installment will be the
selectfunction. -
More than the absence of problems
Quality can be defined in many ways: ISO defines quality relative to requirements as a measure of how well the object’s characteristics meet those requirements. Those requirements can be specified (documented) or implied (customary). This has the advantage of making quality more or less measurable, but it has the disadvantage of making it harder to justify improving the product if the (minimum) requirements are met.
In my view, quality is a measure of excellence: it is more than the absence of problems and aims towards the prevention of problems.
-
When the cup is full, carry it level
It is both a problem and a privilege to have too much work. It is a problem because, at some point, things don’t get done and it is a privilege because it means, among other things, that people are trusting you with things to do.
The C++ for the self-taught podcast, however, is one of the things I am not getting done this time. I will, therefore, have to revert to the original, monthly, schedule for the time being, while I get all the work I have, done.
-
Annoying Script Kiddies
I don’t host any of my sites, except for git.vlinder.ca, myself: my Internet connection isn’t reliable enough, power outages are too frequent, and it’s basically too much of a hassle. So, my sites are hosted by a professional hosting service and that service is responsible for the security of those sites. How annoying is it, then, when three of those sites get cracked through the FTP server?
-
Events in SOA
In a recent article on ZDNet, Joe McKendrick writes that Roy Schulte, the Gartner analyst who helped define the SOA space more than a decade ago, says as SOA becomes embedded into the digital enterprise realm, organizations are moving services to support event-driven interactions, versus request/reply interactions.
This, of course, is old news…
-
Why IPv6 Matters
Given the rapid growth of the Internet, and the number of Internet-enabled devices, we are running out of IPv4 addresses - fast. This is a problem mostly for ISPs and large businesses who allocate their own public IP addresses from pools of addresses and sell or sub-let those addresses to .. us. When they run out of addresses, as with any finite resource, the haves will once again be pitted against the have-nots and the Internet will become less egalitarian. But that is not the only reason why you should be interested in IPv6: more important than the 340 trillion, trillion, trillion addresses that the 128-bit address space of IPv6 allows (as opposed to the “mere” four billion of IPv4) are IPv6’s other features.
-
Refactoring Exceptions
As I mentioned in the previous installment, our current way of handling exceptions leaves a few things to be desired. In this installment, we will fix that problem.
-
Negotiation: first steps
As discussed last month, the requirement for encapsulation pushes us towards allowing the user to know that there’s a negotiation between the two peers, and does not alleviate the requirement that the user understand the errors. So in this installment, we will start using the new implementation of exceptions we worked out in the previous installment, and start on the negotiation mechanism from two installments ago.
-
Is technology making us sick?
In my view, technology should make our lives easier - that’s what I try to work for, that’s what this blog is about and that, in general, is what at least fundamental research is aimed at. But are we going about it the wrong way? Is technology really making our lives harder, rather than easier?
-
Updated: Not-so-permanent permalinks (all permalinks changed)
Due to the addition of an important feature on the site, all permalinks for all posts have changed. Following the old links will send you to an error page where the the proposed options should include the page you’re looking for.
Sorry for the inconvenience.
2010-09-28: to make sure everything continues to work, I’ll be using less pretty, but more effective permalinks as per the default of the blogging engine, from now on. Only one additional permalink is broken with this change, but it does actually fix a few bugs, so I guess I’ll live with the one broken link.
Again, sorry for the inconvenience, but if all goes well, things will get more convenient from here on.
-
Error handling in C++
As far as error handling is concerned, C++ has all of the features and capabilities of C, but they are wholly inadequate in an object-oriented language. One very evident way in which C-style error handling is inadequate in an object-oriented language is in the implementation of a constructor of any non-trivial class, but this only becomes evident when we’ve analyzed two things: the guarantees that any method (including special methods such as constructors and destructors) can give, and the minimal guarantees that each of these special methods must give.
-
Bill #c32 seems to be getting less controversial
Copyright is an important part of my work: every time I sign a work-related contract, I have to make sure that I don’t sign away the rights of previous works to which I retain the rights, nor the rights to work that I do outside the scope of the contract I am signing at that point. I spend a significant amount of time and energy creating copyrighted material and some of that material has to remain mine. Like any copyright bill would, bill C-32 provides a framework to fall back on when cases aren’t covered by contract and now, it looks like it’s on its way to be passed.
-
Home Search, Where Art Thou?
In my day to day life, there are few things I truly dislike doing: I’m a pretty happy person. There is one thing, though, that I really don’t like - at all - and that strikes me as a truly pointless exercise in futility: searching. Shouldn’t we have a solution for that by now?
It strikes me we already have all of the necessary technology to come up with a viable solution: I’ve worked with most of them! Let’s have a look what this might look like.
-
"Given the existence of A, B will create itself, therefore, C had nothing to do with it"
Stephen Hawking’s new book promises a lot of hype. CNN Already published two separate articles about it on their site even though no-one has read it yet. I’ve added it to my Amazon Science Books Wishlist, and will buy it when I come round to it unless some generous soul wants to offer it to me first. About the hype, though:
-
Opacity: Encapsulation at its best (and worst)
One thing you may have noticed when looking at the code of our abstract factory, is that the base classes (interfaces) of each of our abstract objects don’t have much to tell their users: there are hardly any accessors or mutators to be found. This is an attribute of encapsulation called opacity and in this installment, we’ll explore its advantages and disadvantages.
-
Women in computing
When I ran a team of R&D; programmers, a while ago, at one point, we had one person from a visible minority, one person with a slight handicap, two women, two immigrants (one of which was one of the two women, the other was me) and at least one phytopathologist (me). We beat most of the statistics with that team, because there were about ten of us at the time. One of the members of my team remarked that it was the first time he’d worked in a team with two women in it - and he had worked in larger teams before.
-
Tell me twice
A few days ago, I explained to a colleague why certain communications protocols have a “tell me twice” policy - i.e. to allow for any command to have any effect, the same command - or a command to the same effect - has to be received twice (from the same master). In human parlance, this would be the equivalent of Jean-Luc Picard saying “ensign, I’m about to tell you to lower the shields” … “ensign, shields down!” in which the ensign (Wesley Crusher?) wouldn’t be allowed to obey the second command unless he had heard, understood and acknowledged (HUA!) the first. Now for the math..
-
Once burned, twice shy
“Is Good Code Possible?” John Blanco asks on his blog. He goes on to tell a harrowing story on how he had to develop an iPhone app for a big retailer (“Gorilla Mart”) in less than two weeks. Why he even accepted the contract is beyond me but then, he may not have had a choice.
In the scenario he described, there’s really little chance of creating quality code, unless…
-
Socks 5: Credentials on Windows
In this installment, we will continue our implementation of GSSAPI/SSPI, this time on Windows, where we’ll try to get some credentials.
We will look at two topics this time: first, we’ll look at data encapsulation, after which we’ll look at when RAII is a bit too much, and how to handle that.
-
On the Importance of Coverage Profiling
Coverage profiling allows you to see which parts of the code have been run and are especially useful when unit-testing. Here’s an anecdote to show just how important they can be.
-
Socks 5: Expanding the factory
In this installment, we will expand the
MechanismFactoryclass for SSPI. We will take a slightly closer look at the SSPI call than we would normally do, and we will also take a look at the Unicode/”ANSI” differences on Windows. Because of this, we will not have time to take a look at the GSS-API side of things, which we will therefore look into next time around. -
TPM on your content under #c32 - handing away your rights?
Under bill C-32 it would be illegal to remove TPM under by far most circumstances. Does that mean that, if you decide to publish software you create with TPM, you’re handing away the rights of your software to the TPM manufacturer? No, it doesn’t.
-
TPM and the Public Domain (#c32)
Accroding to The Appropriation Art Coalition applying TPM to public domain content effectively removes that content from the public domain. Is that really true? I don’t think so, and here’s why.
-
Is TPM bad for Open Source? (#c32)
It’s been argued that TPM and bill C-32 are bad for Free/Libre Open Source Software development. Is that true? If so, why? If not, why not? Personally, I don’t think so, and I’ll tell you why.
-
Feedback on #C32: Constructive, Destructive or Pointless?
While some of the feed-back on bill C-32 (Copyright reform) seems to be constructive, much of it has become a foray of personal attacks on Conservative MP and Minister of Canadian Heritage and Official Languages, James Moore, who tabled the legislation with Tony Clement, Minister of Industry, on June 2. Of course, his remarks on the subject weren’t very welcome either, calling opponents of the bill “radical extremists”. So, the debate is on on what should probably be one of the more boring subjects in Ottawa: copyright legislation.
-
Bill C-32
A few days ago, I was listening to the podcast for the CBC program Spark, in which they mentioned a new bill, bill C-32. They had a person on the show, whose name I do not remember, who said it was a very “balanced” bill. That peaked my interest, so I decided to read the bill myself.
-
Socks 5: Starting GSS-API - The Factory Pattern
In this installment, we’ll be doing a final bit of clean-up and starting to implement a GSS-API/SSPI client program, while focusing on the Abstract Factory Pattern
-
Binary Search
While going through some old code, for another article I’m writing that will come up on the blog, I came across an implementation of binary search in C. While the implementation itself was certainly OK, it wasn’t exactly a general-purpose implementation, so I thought I’d write one and put it on the C++ for the self-taught side of my blog. While I was at it, I also analyzed
-
Lock-Poor Stack
The following is the complete code of a lock-poor stack in C/C++: it’s mostly C but it uses Relacy for testing, so the atomics are implemented in C++. With a little work, you can turn this into a complete C implementation without depending on relacy. I wrote in while writing an article that will soon appear on this blog.
The stack is not completely lock-free because it needs a lock to make sure it doesn’t need any memory management solution for its reference to the top node during popping or reading the top node.
-
Quantum teleportation achieved over 16 km
Recently, in this report, it’s been reported that a physics laboratory in China achieved a new distance record in quantum teleportation: 16 km. That’s quite a feat, considering that up until now, the max. distance had been a few hundred meters.
-
Albion College decides to scrap Computer Science and Journalism majors
I came across this article while surfing the web this afternoon
-
Creation of a Bacterial Cell Controlled by a Chemically Synthesized Genome
D.G. Gibson et al. reported, in Science Magazine, the “Creation of a Bacterial Cell Controlled by a Chemically Synthesized Genome”. Now, I used to be a biologist and have studied this particular type of biology for a number of years before leaving the field, mostly for financial reasons, for a career in computer science. I’m also a certifiable geek, as I think most of the readers of this blog are, so I thought I’d explain what this means, in geek terms.
-
Socks 5: Finishing sending a token
In this installment, we will finish the implementation for sending a token from the client to the server. We will answer the remaining open questions and, in doing so, improve the code a bit more. When we’re done, we will have a client that sends a token to the server, and a server that reads the token and parses its envelope - which is a pretty good foundation to build on. We will later make that foundation a bit more solid by removing the classes involved from the test code and moving them to their final locations. First, however, let’s take a look at those questions and the answers.
-
Software development productivity
In the latest installment of my podcast, I asserted that “all software productivity problems are project management problems”. In this post, I will explain why I believe that to be the case and how I think those problems can be resolved.
-
Speaking different languages
As a dutchman living in Quebec, Canada - one of those parts of the world where francophones (french-speaking people) are surrounded by anglophones (english-speaking people) and yet thrive speaking french almost exclusively - I sometimes run into the “corner cases” of language related coding standards - e.g. the language comments are supposed to be written in.
-
Socks 5: Continuing Sending a Token - Anecdote
Recording the latest episode of the podcast reminded me of a story that I’d like to tell you: a few years ago, I started working as a programmer on a project in which there was a policy to include the definitions of the classes used in a header - by including the headers that defined those classes - rather than what I recommended in the podcast: to use forward declarations. They also had a policy to use only the name of the file to include rather than the complete path (e.g.
#include "MyClass.h"rather than#include "path/to/MyClass.h"). The reason for this was convenience: the preprocessor, when told where to look, would find the proper files and including them in the class’ header meant you didn’t have to use dynamic allocation (of which there was still a lot going on in the project) but you could use the objects directly, rather than references and pointers. -
Did I say 5000? Make that 14000(!)
-
SOCKS 5 Step 2: exchanging a token
With a few minor adjustments to the existing
Tokenclass, we can finish the first part of our implementation of RFC 1961 for now - we will hook it into an implementation of the GSS API later. -
Thanks for listening - 5000+ downloads
-
Preprequisites for the project
In this installment, we’ll get you set up to compile everything that needs compiling in our project. We’ll try to keep it short and sweet and you’ll be able to download most of what you need just by following the links on this page.
-
Use-Cases Part 3: What A Use-Case Really Is & Writing Use-Cases
Before we start using use-cases in the description of the functional requirements we want to meet in our project, we need to understand what a use-case really is and how to go about writing one. In this installment I will attempt to answer both those questions. However, this series is called “C++ for the self-taught” for a reason: I will include references for all of the material I have cited in this installment, and I hope you will take it upon yourself to go out and look a bit yourself as well.
-
Use-Cases Part 2: What Use-Cases Are For (The history, present and future of use-cases)
In the late 1980s and early 1990s, the “waterfall” software development model, which had been around (with that name) since the 1970s (see, for example, Boehm, B.W. Software engineering. IEEE 7~ans Comput. C-25, (1976), 1226-1241) was starting to be progressively “refined”. When that happens, it usually means that there are problems with the model that need to be addressed - or the model will crumble and fall. Object-oriented programming was becoming more or less main-stream and early versions of C++ were cropping up. “Good practice” documents for programming on non-OO languages started to stress the use of OO-like APIs and soon enough, object-oriented programming would no longer be a mere buzzword.
-
The answer to the quiz in episode 7 of C++ for the self-taught
I know you must have been aching for the response to the quiz from three weeks ago. If you haven’t thought of your own answer yet, go back to the code and have another look. Try running it through a compiler with all the warnings turned on - it might tell you what the bug is (more or less), but probably not how to solve it.
-
Use-Cases Part 1: Introduction & Ingredients
In the “C++ for the self-taught” series, we’re about to embark on a new project. In order to describe that project and in order to figure out what we want the result of that project will be, we will be using a tool called the use-case. So, I think an intermezzo on use-cases is in order.
-
Confusing the compiler
Sometimes it’s real fun to see how easily you can confuse the compiler. In the error below,
functionis a macro that takes three parameters:filename.c(453) : error C2220: warning treated as error - no 'object' file generated filename.c(453) : warning C4013: 'function' undefined; assuming extern returning int filename.c(466) : error C2064: term does not evaluate to a function taking 279509856 argumentsI don’t know where it got the idea that I typed 279,509,856 parameters, but I sure didn’t take the time to do that! ;)
-
7- Polymorphism
In this last installment before we start our development project (and yes, there is a development project coming) we will talk a bit about the C++ type system, how to use it, how it ties in with object-oriented programming and how it ties in with what we’ve discussed earlier. We will see what the
virtualkeyword is all about, and how “a duck is a bird, is an animal” and “a table and a chair are both pieces of furniture” comes into play, and is expressed in C++. Once we’ve gone through that, you’ll be sufficiently equipped for object-oriented programming in C++. -
Error handling in C
One of the things I do as a analyst-programmer is write software - that would be the “programmer” part. I usually do that in C++ but, sometimes, when the facilities of C++ aren’t available (e.g. no exception handling and no RTTI) C becomes a more obvious choice. When that happens, RTTI is not the thing I miss the most - you can get around that using magic numbers if you need to. Exceptions, on the other hand, become a very painful absence when you’re used to using them.
-
Distributed Software Development Part 3: Tools Of The Trade
For software development, there are a few things we need on a daily basis: our source code, our documentation, our integrated development environment (IDE) and our hardware. Without any one of these, a software developer is as useless as… well… something very useless.
-
6- Resource Allocation and RAII
In standard C++, there is no garbage collector: there is no built-in mechanism that will magically clean up after you if you make a mess. You do, however, have the possibility to allocate resources, such as memory or files, and work with them. You should, therefore, be able to manage them consistently so you don’t “leak” them.
-
Distributed Software Development Part 2: Management Challenges
Business is largely about management which, in turn, is largely about reducing costs and reducing time-to-market. However, today’s management models for human resources are largely based on two things: physical presence in the office and seniority. Performance is often only part of the equation when it comes to promotion - people tend to get promoted upto their level of incompetence - and bonuses. In the software industry, however, management models are changing towards a more participatory model in which managers have less and less to say on the “how”, the “who” and the “when” of the development process but, in return, get more say in the “what” - the customer gets to say “why”. In some forms of agile development, team members can even be “voted off the island”, which can be very disconcerting indeed for the manager.
-
Distributed Software Development Part 1: The Safe Boom
As I said in a previous post, the new economic realities that come with peak oil and climate change will change the way we work and the way the computing industry is run. One of those changes will be limiting unnecessary costs related to moving people around - something we already do for goods.
-
5- Objects, References and Pointers
The difference between references and pointers, what they are w.r.t. pointers and how to handle each has often been the source of confusion, sometimes even for seasoned programmers and often for formally trained, inexperienced programmers. Very often, especially in legacy code, I find one if the ugliest constructs imaginable: a function that returns a reference that is the result of dereferencing a pointer, if which the address is subsequently taken to validate its value. Ugh!
-
Staring into the depths of the yet unwritten
By the end of the next decade, there will be no oil left for consumers such as myself and we’ll have reached peak oil. By the end of the decade after that, the last wild polar bear will have drowned because there will be no polar ice left for it to walk on, it will have been shot by some-one up North as it entered a home looking for food, or it will have died of starvation after eating the last of its cubs. By the end of my expected natural life-span, there will be no edible fish left in the ocean.
These statements, which are corroborated by leading economist and, for the one about the polar ice cap, meteorologists rather than environmentalists, have a profound impact on the way we work and on the computing industry in general.
-
4- Classes
In any language that supports object-oriented programming, the class is a, if not the, basic building block. In this post, we’ll take a closer look at what a class is, and how that ties in with what we’ve seen in the previous post, data structures, and in the two next posts: pointers, references, objects and RAII.
-
Microsoft Team Foundation Server vs Git
For the last few weeks, and in the coming months, I’ve had to (and will have to) work with Microsoft’s Team Foundation Server (TFS).
-
Implicit, Contextual Requirements
We tend to forget what we know implicitly: if we’ve been working in the same domain for long enough, we tend to forget that not everybody knows the same things and has the same experience we do. For example, some-one who has been working in distribution for a long time may think it’s obvious that, even if you do switch to RFID, you will still need line-of-sight machine-readable codes (because RFID might fail and because the technology for using line-of-sight machine-readable codes is much mire ubiquitous than RFID is) and when they think of line-of-sight machine-readable codes, they think of barcodes and, depending on what and where they distribute, they might think of Data Matrix codes, UPC-12 codes, or any number of other barcodes.
-
A Day In The Life Of A C++ Analyst/Programmer
While listening to Spark, on CBC Radio, I had the idea it might be nice for non-developers (and aspiring developers) to know what a typical day might look like.
-
3- Data Structures
Before we delve into the realm of object-oriented programming (which we will get into in the next post), there is a notion that is so basic, and so important to any type of programming, that we have to treat it in order to make the whole notion of object-oriented-programming comprehensible.
-
The Quest For Bug-Free Software
In recent literature from the scientific side of software engineering, there’ve been a lot of publications on producing and maintaining high-quality software. A lot of focus is being put on tools, systems, procedures and processes that aim to reduce the price-tag of quality and avoid the price-tag of failure.
-
2-Control Structures
In this post, we’ll take a look at a few control structures in C++. There are only a few of them, so we’ll start by listing them all and giving you some examples of each, but we’ll first take a look at what we mean by control structures.
-
Badly defined semantics
There is probably nothing worse than badly defined semantics: functions that might (or might not) take ownership of the object you pass to them can be a serious maintenance headache.
-
Protect what's yours
I’ve drawn up a list of my intellectual property yesterday. It’s about four pages long and contains libraries, applications, web apps, training material, etc. Only one thing that I’ve ever created and published is in the public domain - the rest has copyrights attached to it. That doesn’t necessarily mean that you can’t use it, or even that you have to pay me to be allowed to use it: it just means that it’s mine and that I decide what kind of rights you have over it.
-
1- "Hello, world!"
This is the first post in the “C++ for the self-taught” series - the second if you count the introduction. We will take a look at how to create your first C++ application.
-
C++ for the self-taught: Introduction
I’ve decided to take a little time to make use of those 20000+ hours of C++ I have under my belt and make life a bit easier on those of you that are learning C++. In order to do that, I have created a new category called “C++ for the self-taught” that will basically show you how to program in C++.
-
Rapid application development in PHP
For the last few days, I’ve been out of my usual C++ cocoon and working, in stead, on a web app to help me better organize my projects and - more especially - help me better track them.
-
The importance of meaningful work
-
Developer's Guidelines & High-Quality Software
Yesterday, I was asked what I saw as the most important factors to ensure the development of quality software. What I cited was good design, good implementation following good standards, and good testing.
-
Security at the Design Phase - Examples & Review
A recent report from the SEI confirms once more what I have been saying for a few years now: security is a design-time concern as much as it is a concern at any other time during the application life-cycle. The very architecture of the application should take security into account from the outset, and that concern should be followed through down to implementation and deployment.
-
Can Agile and CMMI Come Together?
I just finished reading a report by the Software Engineering Institute that accomplishes something that earlier literature, including “SCRUM Meets CMMi - Agility and discipline combined” didn’t accomplish: it takes a rational step back from both methods, shows where they’re from and why they’re different, how much of that difference is real and where the perceived differences come from, and how the two can come together. So, the short answer to my title is “yes”.
-
Installing Git on CentOS 5.2
I’m pretty sure that I’m not the first one to run into this, so I thought I’d blog how this works.
-
Out-of-touch techies, marketing retoric, and nonsense. You do the math.
Sometimes, techies and marketers - and especially people who are both - can get very out-of-touch with the real world and start spewing out nonsense
-
A new theme
I promised I wouldn’t talk about this blog too much on the blog, and I promise I won’t do this often, but I thought it might be a good idea to notice that I’ve made a few minor changes.
-
Running a LAMP: Debian vs. CentOS
One of my clients uses CentOS for the production platform of their (web) application (written in PHP). They’ve asked me to take over the development and maintenance of their web application, so, naturally, I set up a new server with CentOS 5.2, rather than the Debian installation I would normally use.
-
Having fun on a technical test
I guess it’s not a secret: I’m looking for a job, either short-term or long-term, so I put my CV on a few websites. I got called by head-hunters twice this week: once for a contract to start on Monday (I’m busy until the end of September/the beginning of October so I told ‘em I couldn’t start full-time until then) and one to start a bit later.
-
The Importance of Proof-Of-Concepts
Any problem is an invitation to find a solution.
-
Refreshing SQL
I first started working with SQL several years ago: MySQL was still in the 3.x versions, so I didnt use any stored procs, transactions, etc. Most of the business logic around the data was written in Perl. Though it was a fun time in many respects, I dont miss the limitations of MySQL one bit.
-
Binary Compatibility
When writing library code, one of the snares to watch out for is binary compatibility. I have already talked about the dangers of breaking binary - and API - compatibility but I had neither defined what binary compatibility is, now how to prevent breaking it. In this post, I will do both - and I will explain how, at Vlinder Software, we go about managing incompatible changes.
-
The Danger of Breaking Changes
Xerces-C is without a doubt one of the most popular DOM implementations in C++ (and its Java sibling undoubtedly the most popular implementation for Java). As with any project that lives under the banner of the Apache Foundation the project is managed using a meritocracy-style project management scheme and has been, quite successfully, for the last decade.
-
The Importance of Patterns
When explaining the design of some application to some-one, I find the use of analogies is one of the best tools available to me - better than diagrams and much better than technical terms: when using technical terms, the listener often starts “glazing over” after only a few seconds - maybe a minute. It really serves no other purpose than showing off how smart you are - and that is usually a pretty stupid (and therefore self-defeating) thing to do.
-
Naming conventions and name mangling
In C++, any name that starts with and underscore followed by an uppercase letter and any name that contains two consecutive underscores is reserved for any use [lib.global.names] and any name that begins with an underscore is reserved in the global namespace.
-
Using Four-Letter Words In Code
When writing firmware and device drivers, it is useful, sometimes, to have human-readable integer values - i.e. integer values that, when you read them in a debugger, mean something distinctive.
-
Mail down - and back up again
I changed my hosting provider a few days ago, which implied changing the DNS provider as well. As a result of this - and my forgetting to set the MX entry correctly, the mail service for landheer-cieslak.com was down. Michel was kind enough to notify me of this, so it’s been fixed this morning.
-
Name For Functionality, Not Type
I just read a blog by Michel Fortin, where he quotes Joel On Software regarding Hungarian notation, or rather, Hungarian WartHogs. Naming a variable for its type, or a type for its location or namespace, is a mistake.
-
Hiding Complexity in C++
C++ is a programming language that, aside from staying as close to the machine as possible (but no closer) and as close to C as possible (but no closer), allows the programmer to express abstraction if a few very elegant constructs. That is probably the one thing I like best about C++.
-
Crime, Debugging and the Broken Window Rule
In the late 1980s New York City was cleaned up from under the ground up: from 1984 to 1990, the New York subway was cleaned of its grafiti, then of its non-paying passengers. After that, when the chief of tge New York transit police became the chief of the New York city police, the city was cleaned up in the same way, and crime rates dropped dramatically.
-
How Data Transport Should Work IMNSHO
One of the most ubiquitous problems in software design is to get data from one place to another. When some-one starts coding code that does that, you seem to inevitably end up with spaghetti code that mixes the higher-level code, the content and the transport together in an awful mix that looks like a cheap weeks-old spaghetti that was left half-eaten and abandoned next to a couch somewhere. Now, I have never seen what that actually looks like, but I have a rather vivid imagination - and I’ll bet you have too.
-
Google releases new dialect of Basic
And here I though Basic was on its way out: Microsoft has been touting the advantages of C# and .NET in general far more than they have the advantages of Visual Basic (I remember when it became “visual”: it used to be “quick” and that never said anything about run time); and Google seemed to be much more interested in Python and Java than they were in the whole Basic scene. In the circles I’ve frequented for the last several years, Basic was used only in ASP applications and then only if, for some reason, using C# was out of the question. Basic was basically legacy code that hadn’t been replaced yet.
-
Testing QA
During the development of the next version of Funky, version 1.4.00, I found a bug that hadn’t been picked up during the release process for 1.3.00. Though the bug was in a corner of the interpreter that was new to version 1.3.00 and didn’t cause anything too nasty - just a case where the interpreter rejects a script as invalid when it’s not - it does mean an actual bug got through QA. I hate it when that happens.
-
Fixing mistakes
I just finished debugging a very, very nasty problem, which took me the better part of two hours to find and, once found, only a few minutes to fix. In this case, I have no one to blame but myself, so I really shouldn’t complain too loudly, but I thought it was worth mentioning anyway, to show what can happen if you break the One Definition Rule.
-
Working on a programming language
Like a warm spring breeze writing is to summer's dawn as language to dusk -
Culture and working internationally
When autumn turns hence to where winter must come forth spring awaits summer -
Google Chrome OS: Promising - but promising what, exactly?
is this coming spring or is't autumn in disguise? spring doth promise much! -
Funky, functional programming and looping
functional combines programming summers into sheerly fun coding -
Storing data in an optical illusion
For the past five years now, I’ve worked on vision inspection systems for the pharmaceutical industry. In those years, I have seen many applications in which cameras were used to read data on bottles, cartons, even tablets. Barcodes can be printed almost anywhere and can be of almost any size. One application I’ve worked on - with a whole bunch of other people, of course - had Optel Vision systems inspect datamatrix 2D barcodes with ten digits in it (a 12x12 ECC200 datamatrix) printed on only 3x3 mm on the neckband of a vial. The system had to be able to inspect several dozens of these a minute, using VGA resolution cameras - and they were small enough that it was hard to find them if you didn’t know where they were. Let’s just say this was one of the more challenging systems.
-
Critical sections - of what?
a glass of water may sometimes have a storm, but blizzards there are rare -
A glimmer of hope on comp.std.c++
Sun to early spring is like snow is to autumn: unexpected joy -
Ah - The One Definition Rule
In response to Scott Meyers’ question on non-inline non-template functions and the one-definition rule, Francis Glassborow replied with a very interesting example of two lexically identical functions that weren’t actually identical.
-
Recursive Locking Is Evil, or is it?
recursive locking: winter's way of saying "yes", to summer's loud "no" -
No Concepts in C++0x
Sadness of winter decided this summer, when no concept survived -
Why you shouldn't inflate your resume
Many people inflate their resumes when they apply for a job. When I’m on the hiring side of the equasion, I tend to frown upon such practices: though I usually don’t care much about references, I do check the outliers. But what I check more is expertise - and that’s something I can’t stand inflation on.
-
@msofficeus @fixoutlook - what's the big deal?
flabbergasted I long for winter in summer? perhaps just autumn -
Seven?
Clarification as clarity of summer - yet not unlike spring. -
How to become an expert
Many summers spent on coding and on code, yet... expertise attained? -
The IKEA Approach
spring cleaning brings it perhaps not any cleaner - at least much leaner -
A new blog
the first of summer the very last of winter? the first of blog posts
subscribe via RSS